 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexterity-BEV: Aligning 3D World and Actions for Generalizable Robot Policies Learning
Jun 01, 2026End-to-end manipulation policies, combined with web-scale pretrained Vision-Language Models (VLMs), show the promise for generalizable and dexterous robotic manipulation. However, they inherit two key limitations from 2D foundation models: 1) the reliance on 2D RGB inputs that ignores the intrinsically 3D nature of manipulation; and 2) the lack of spatial 3D alignment between input-output spaces as well as across diverse robot embodiments, camera setups, and trajectory datasets. In this paper, we present a series of contributions to address these issues. First, we introduce aligned vertex map and vertex spectrum -- a pixel-wise 3D representation that elevates 2D visual inputs to 3D, using camera calibration and optional depth. This novel input representation marries 3D awareness with the generalization of 2D large VLMs. Then, we propose to align the inputs and outputs of manipulation policies by expressing per-pixel 3D information of each camera view and robot actions to a shared coordinate. Based on this, we designate a canonical Bird's-Eye-View (BEV) alignment frame and innovatively propose to construct BEV images, producing a view-invariant representation robust to camera pose variations. To enable training and evaluation at scale, we develop a comprehensive data processing pipeline to perform such alignments; we also introduce a novel temporal alignment scheme for trajectories across diverse robots, human operators, and datasets. These contributions collectively mitigate input and output spatial-temporal misalignments, improving the consistency and generalization for real-world manipulation. Pretrained checkpoint, source code and data processing pipeline are available in https://hnuzhy.github.io/projects/Dex-BEV.
Enhancing Generalization of Depth Estimation Foundation Model via Weakly-Supervised Adaptation with Regularization
Nov 18, 2025The emergence of foundation models has substantially advanced zero-shot generalization in monocular depth estimation (MDE), as exemplified by the Depth Anything series. However, given access to some data from downstream tasks, a natural question arises: can the performance of these models be further improved? To this end, we propose WeSTAR, a parameter-efficient framework that performs Weakly supervised Self-Training Adaptation with Regularization, designed to enhance the robustness of MDE foundation models in unseen and diverse domains. We first adopt a dense self-training objective as the primary source of structural self-supervision. To further improve robustness, we introduce semantically-aware hierarchical normalization, which exploits instance-level segmentation maps to perform more stable and multi-scale structural normalization. Beyond dense supervision, we introduce a cost-efficient weak supervision in the form of pairwise ordinal depth annotations to further guide the adaptation process, which enforces informative ordinal constraints to mitigate local topological errors. Finally, a weight regularization loss is employed to anchor the LoRA updates, ensuring training stability and preserving the model's generalizable knowledge. Extensive experiments on both realistic and corrupted out-of-distribution datasets under diverse and challenging scenarios demonstrate that WeSTAR consistently improves generalization and achieves state-of-the-art performance across a wide range of benchmarks.
Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
Oct 02, 2025
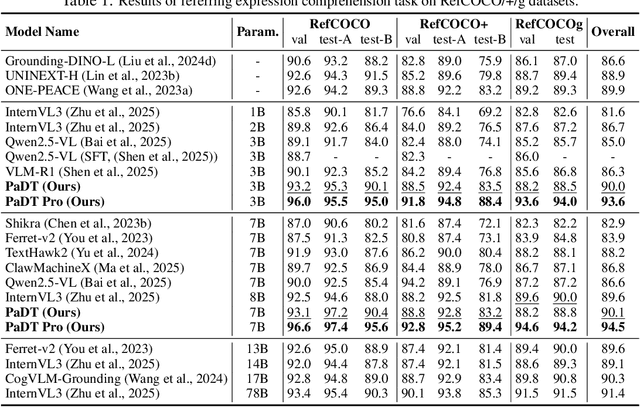

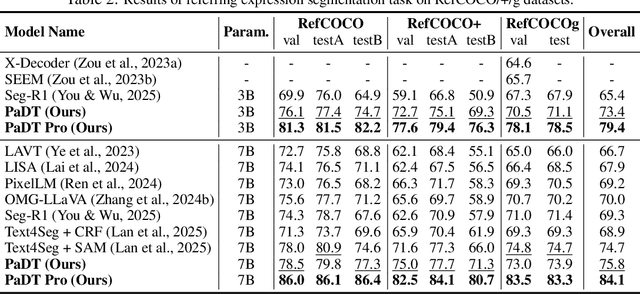
Multimodal large language models (MLLMs) have advanced rapidly in recent years. However, existing approaches for vision tasks often rely on indirect representations, such as generating coordinates as text for detection, which limits performance and prevents dense prediction tasks like segmentation. To overcome these challenges, we introduce Patch-as-Decodable Token (PaDT), a unified paradigm that enables MLLMs to directly generate both textual and diverse visual outputs. Central to PaDT are Visual Reference Tokens (VRTs), derived from visual patch embeddings of query images and interleaved seamlessly with LLM's output textual tokens. A lightweight decoder then transforms LLM's outputs into detection, segmentation, and grounding predictions. Unlike prior methods, PaDT processes VRTs independently at each forward pass and dynamically expands the embedding table, thus improving localization and differentiation among similar objects. We further tailor a training strategy for PaDT by randomly selecting VRTs for supervised fine-tuning and introducing a robust per-token cross-entropy loss. Our empirical studies across four visual perception and understanding tasks suggest PaDT consistently achieving state-of-the-art performance, even compared with significantly larger MLLM models. The code is available at https://github.com/Gorilla-Lab-SCUT/PaDT.
AD-FM: Multimodal LLMs for Anomaly Detection via Multi-Stage Reasoning and Fine-Grained Reward Optimization
Aug 06, 2025



While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities across diverse domains, their application to specialized anomaly detection (AD) remains constrained by domain adaptation challenges. Existing Group Relative Policy Optimization (GRPO) based approaches suffer from two critical limitations: inadequate training data utilization when models produce uniform responses, and insufficient supervision over reasoning processes that encourage immediate binary decisions without deliberative analysis. We propose a comprehensive framework addressing these limitations through two synergistic innovations. First, we introduce a multi-stage deliberative reasoning process that guides models from region identification to focused examination, generating diverse response patterns essential for GRPO optimization while enabling structured supervision over analytical workflows. Second, we develop a fine-grained reward mechanism incorporating classification accuracy and localization supervision, transforming binary feedback into continuous signals that distinguish genuine analytical insight from spurious correctness. Comprehensive evaluation across multiple industrial datasets demonstrates substantial performance improvements in adapting general vision-language models to specialized anomaly detection. Our method achieves superior accuracy with efficient adaptation of existing annotations, effectively bridging the gap between general-purpose MLLM capabilities and the fine-grained visual discrimination required for detecting subtle manufacturing defects and structural irregularities.
Robust Distribution Alignment for Industrial Anomaly Detection under Distribution Shift
Mar 19, 2025



Anomaly detection plays a crucial role in quality control for industrial applications. However, ensuring robustness under unseen domain shifts such as lighting variations or sensor drift remains a significant challenge. Existing methods attempt to address domain shifts by training generalizable models but often rely on prior knowledge of target distributions and can hardly generalise to backbones designed for other data modalities. To overcome these limitations, we build upon memory-bank-based anomaly detection methods, optimizing a robust Sinkhorn distance on limited target training data to enhance generalization to unseen target domains. We evaluate the effectiveness on both 2D and 3D anomaly detection benchmarks with simulated distribution shifts. Our proposed method demonstrates superior results compared with state-of-the-art anomaly detection and domain adaptation methods.
Augmented Contrastive Clustering with Uncertainty-Aware Prototyping for Time Series Test Time Adaptation
Jan 01, 2025



Test-time adaptation aims to adapt pre-trained deep neural networks using solely online unlabelled test data during inference. Although TTA has shown promise in visual applications, its potential in time series contexts remains largely unexplored. Existing TTA methods, originally designed for visual tasks, may not effectively handle the complex temporal dynamics of real-world time series data, resulting in suboptimal adaptation performance. To address this gap, we propose Augmented Contrastive Clustering with Uncertainty-aware Prototyping (ACCUP), a straightforward yet effective TTA method for time series data. Initially, our approach employs augmentation ensemble on the time series data to capture diverse temporal information and variations, incorporating uncertainty-aware prototypes to distill essential characteristics. Additionally, we introduce an entropy comparison scheme to selectively acquire more confident predictions, enhancing the reliability of pseudo labels. Furthermore, we utilize augmented contrastive clustering to enhance feature discriminability and mitigate error accumulation from noisy pseudo labels, promoting cohesive clustering within the same class while facilitating clear separation between different classes. Extensive experiments conducted on three real-world time series datasets and an additional visual dataset demonstrate the effectiveness and generalization potential of the proposed method, advancing the underexplored realm of TTA for time series data.
Efficient and Context-Aware Label Propagation for Zero-/Few-Shot Training-Free Adaptation of Vision-Language Model
Dec 24, 2024



Vision-language models (VLMs) have revolutionized machine learning by leveraging large pre-trained models to tackle various downstream tasks. Despite improvements in label, training, and data efficiency, many state-of-the-art VLMs still require task-specific hyperparameter tuning and fail to fully exploit test samples. To overcome these challenges, we propose a graph-based approach for label-efficient adaptation and inference. Our method dynamically constructs a graph over text prompts, few-shot examples, and test samples, using label propagation for inference without task-specific tuning. Unlike existing zero-shot label propagation techniques, our approach requires no additional unlabeled support set and effectively leverages the test sample manifold through dynamic graph expansion. We further introduce a context-aware feature re-weighting mechanism to improve task adaptation accuracy. Additionally, our method supports efficient graph expansion, enabling real-time inductive inference. Extensive evaluations on downstream tasks, such as fine-grained categorization and out-of-distribution generalization, demonstrate the effectiveness of our approach.
On the Adversarial Risk of Test Time Adaptation: An Investigation into Realistic Test-Time Data Poisoning
Oct 07, 2024



Test-time adaptation (TTA) updates the model weights during the inference stage using testing data to enhance generalization. However, this practice exposes TTA to adversarial risks. Existing studies have shown that when TTA is updated with crafted adversarial test samples, also known as test-time poisoned data, the performance on benign samples can deteriorate. Nonetheless, the perceived adversarial risk may be overstated if the poisoned data is generated under overly strong assumptions. In this work, we first review realistic assumptions for test-time data poisoning, including white-box versus grey-box attacks, access to benign data, attack budget, and more. We then propose an effective and realistic attack method that better produces poisoned samples without access to benign samples, and derive an effective in-distribution attack objective. We also design two TTA-aware attack objectives. Our benchmarks of existing attack methods reveal that the TTA methods are more robust than previously believed. In addition, we analyze effective defense strategies to help develop adversarially robust TTA methods.
Exploring Human-in-the-Loop Test-Time Adaptation by Synergizing Active Learning and Model Selection
May 29, 2024



Existing test-time adaptation (TTA) approaches often adapt models with the unlabeled testing data stream. A recent attempt relaxed the assumption by introducing limited human annotation, referred to as Human-In-the-Loop Test-Time Adaptation (HILTTA) in this study. The focus of existing HILTTA lies on selecting the most informative samples to label, a.k.a. active learning. In this work, we are motivated by a pitfall of TTA, i.e. sensitive to hyper-parameters, and propose to approach HILTTA by synergizing active learning and model selection. Specifically, we first select samples for human annotation (active learning) and then use the labeled data to select optimal hyper-parameters (model selection). A sample selection strategy is tailored for choosing samples by considering the balance between active learning and model selection purposes. We demonstrate on 4 TTA datasets that the proposed HILTTA approach is compatible with off-the-shelf TTA methods which outperform the state-of-the-art HILTTA methods and stream-based active learning methods. Importantly, our proposed method can always prevent choosing the worst hyper-parameters on all off-the-shelf TTA methods. The source code will be released upon publication.
CLIP-guided Source-free Object Detection in Aerial Images
Jan 10, 2024



Domain adaptation is crucial in aerial imagery, as the visual representation of these images can significantly vary based on factors such as geographic location, time, and weather conditions. Additionally, high-resolution aerial images often require substantial storage space and may not be readily accessible to the public. To address these challenges, we propose a novel Source-Free Object Detection (SFOD) method. Specifically, our approach is built upon a self-training framework; however, self-training can lead to inaccurate learning in the absence of labeled training data. To address this issue, we further integrate Contrastive Language-Image Pre-training (CLIP) to guide the generation of pseudo-labels, termed CLIP-guided Aggregation. By leveraging CLIP's zero-shot classification capability, we use it to aggregate scores with the original predicted bounding boxes, enabling us to obtain refined scores for the pseudo-labels. To validate the effectiveness of our method, we constructed two new datasets from different domains based on the DIOR dataset, named DIOR-C and DIOR-Cloudy. Experiments demonstrate that our method outperforms other comparative algorithms.